Some of the smaller bimolecular present in living system can polymerize or interact with each other to form much larger molecules known as macromolecules which fall into four major groups i.e. polysaccharides, proteins, lipids, nucleic acid.
Carbohydrates : the energy givers (polysaccharides)
In polysaccharides, units of simple sugar or their derivatives are linked together by glycosidic bond. A glycosidic bond is formed by the elimination of water between the – or group of anomeric carbon atom of sugar and the-or group of usually of on carbon 4 or 6 of another sugar polysaccharides serve as structural components which increases the strength of any tissue. They are located in or serve as storage forms of energy.
In starch and glycogen the-OH group on the anomeric carbon atom is in the ∝ glycosidic region whereas in cellulose the bond formed is β glycosidic.
Homopolysaccharides
If the polysaccharides is built around only one kind of sugar, then it is called homopolysacchared. In animals’ glycogen is an important storage form of glucose present in animal liver and muscles and in plant cellulose is the most abundant biomolecule of cell wall and starch is the storage form of glucose.
Heterpolysaccharide
It two or more different sugar derivatives or residues are polymerized then these polymers are called heteropolysaccharides for eg-peptidoglycans are heteropolysaccharides present in the cell wall of bacteria these impart characteristic shape to bacteria and forms a osmoticlysis.
Nucleic acid
Two different kinds of nucleic acid are present in almost every all
(1) Ribonucleic acid (RNA), (2) Deoxyribonucleic acid
Ribonucleotides and deoxyribonucleotide eliminates water forming linear polymer called RNA and DNA respectively.
The bond formed between the nucleotides is called phosphodiester bond, which is formed between 5’ phosphate group of one nucleotide and 3’ hydroxyl group of other nucleotide therefore also called 5’-3’ phosphodiester bond. RNA-
RNA is single stranded holy ribonucleotide chain.
There are three major forms of RNA found in a cell.
(1) Messenger RNA (mRNA) 5% of total RNA polymer and length in the range 35-3000 nucleotide
It has the information to make protein
(2) Transfer RNA (t RNA) soluble RNA, 15%, 90 nucleotides,
It helps in transferring amino acid during protein synthesis so act as adaptor molecule.
(3) Ribosomal RNA (r RNA) 80% 120-3000 nucleotides
It is associated with sub-cellular structure ribosome along with some protein and provide ribosome their shape. DNA
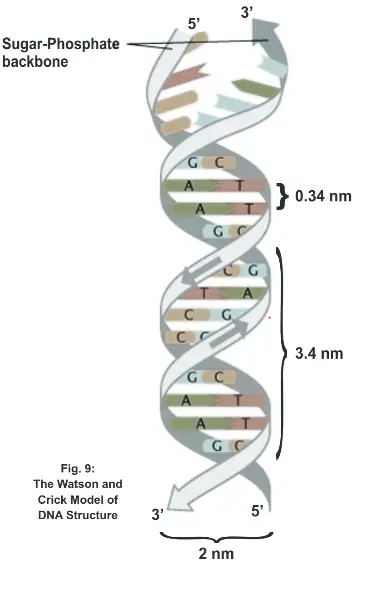
It exist as double stranded structure. Each strand of the DNA a polydeoxyribonucleotide structure in which one end has free 5’ and other has 3’. Double helical model of DNA (By Watson and crick)
(1) DNA is a double stranded structure
(2) Both the strands are anti-parallel to each other.
One strand has 5’ to 3’ polarity other has 3’ to 5’ polarity.
(3) The base sequence on one strand is complementary to the base sequence on other strand because of base pairing rule. Adenine always paired with thymine with two hydrogen bond and guanine always binds with cytosine with 3 hydrogen bonds
5’-A CGTAATGGA-3’
3’-T GCATTACCGT-5’
The biological importance of this information is tremendous. During replication when DNA has to be copied to the daughter cell, the sequence on one stand aligns with the sequence on the daughter cell.
(4) She two stranded structure which can be represented like a step-ladder with the base pair forming the rungs, fold around an imaginary forming a double helical conformation which is either right handed coil. Ex-(B-DNA and A-DNA) or a left-handed (Z-DNA).
DNA is contained is sub-cellular structure known as chromosomes which can be visualized by special staining techniques. In Eukaryotic cell chromosomes are confined to the nucleus such packaging usually involves a process known as super coiling with the help of enzyme ‘topoisomerases’ which keep DNA is a highly super coiled state along with packaging protein such as histones.
Proteins-the performers
Proteins are linear polymers of amino acid wherein a water molecule is eliminated from a carboxylic group of one amino acid and amino group of adjacent amino acid and forming a peptide bond hence proteins are also called polypeptide.
Protein structure
Each protein made up 20 amino acid in different ratios and therefore has a unique amino acid sequence. This difference in composition and therefore difference in sequence is the basis of enormous diversity in function of protein. Proteins fold into extra-ordinary 3-D, structures which in turn give rise to unique function.
Sometimes structure of a protein is altered by a mutation in gene and this leads to a abnormal or malfunctioning of protein. An example is the protein hemoglobin which carries oxygen from lungs to tissue as a part of erythrocytes (RBCS).
When normal form of hemoglobin is present RBC is of concave and can carry normal amount of oxygen to the tissue. A mutant form of hemoglobin lead to sickle shaped RBC of hemoglobin to carry oxygen leading to sickle all anemia.
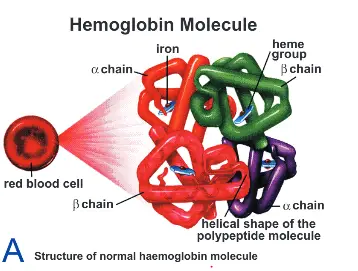
Some proteins are made up of single polypeptide chain (monomaniac) some have more than one chain and are called multimeric. Myoglobin a protein found in muscle contain only one polypeptide chain. Hemoglobin has 4 polypeptide chain of two kinds α and β designated as α2 and β2
Certain proteins contain metal ions in their structure like enzymes carbonic anhydrase which has, Zn2+ ion.
Some proteins have small organic molecules known as “prosthetic group” which can be ‘Horm’ in hemoglobin or vitamin-B complex derivatives known as co-enzymes in many enzymes.
Determination of amino acid sequences (Primary structure)
The complete amino acid sequence of a protein read amino terminal to carboxylic terminal is known as its primary structure.
For the sequence determination it is essential to know the protein’s purity. Molecular weight and its amino acid composition.
A pure protein if multimeric must be dissociated into polypeptide chain and the molecular weight of chain determine which roughly tells about the number of amino acid residues containing. The average molecular weight of each amino acid is approx. 110Da. The first protein to be sequenced was hormone insulin whose deficiency leads to disease diabetes. Fred Sanger invented a method of protein sequencing wing a step wise release and identification of amino acid starting from the N terminal. Pelar Edman developed a sequencing technical which has been automated.
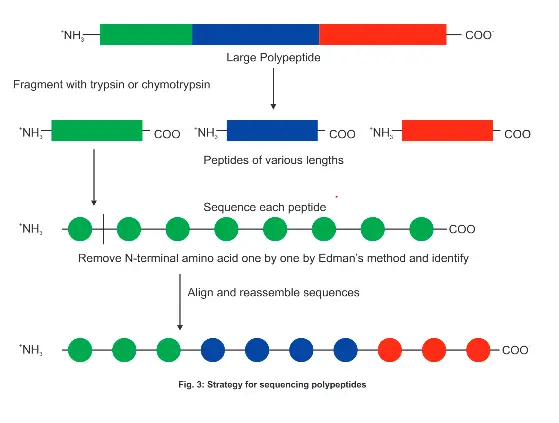
Sequencing Strategy
Sequenater are machine which chemically label the N-terminal amino acid of a poly-peptide release specifically the labeled amino acid residues leaving the rest of the protein shortened by one residue the label amino acid is identified by chromatographic techniques, this procedure is repeated as many times as the number of residues protein contain.
If the protein is large it is leaved by proctologic enzyme such as tripling and chymotrypsin around 50 amino acid residues long and then subject to sequencing.
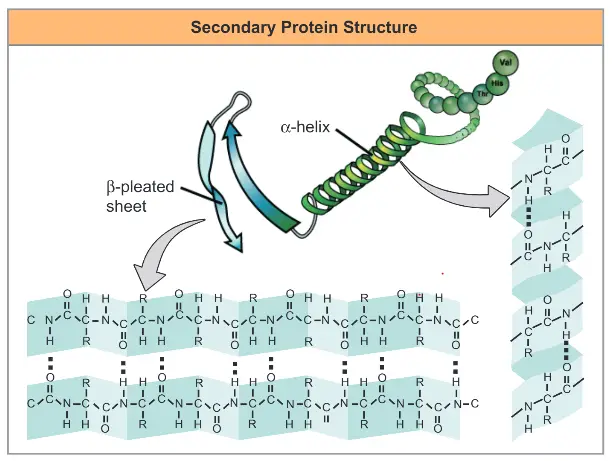
Protein secondary structure ( α helix and β pleats)
The polypeptide chain is not straight and fold about itself to form two main structure α helix and β pleats
α -helix
An α -helix is a spiral structure and depending on the contour of polypeptide backbone can have a right-handed orientation or a left handed one (mostly right-handed helix). Some naturally occurring fibrous protein like keratin which make up the major protein of extradermal tissues such as hairs, hooves and horns predominately have only helix. Hair proteins have spring like structure are extensible.
β pleats
The other secondary-structural Clements known as β pleats is like a sheet like structure wherein two or more section of polypeptide strand come together silk which consist predominantly of the protein silk fibroin is made up of mainly β pleats
The pleat like structure in cell makes the silk fibre strong and non-extensible. Fibroin from some spider web is used to make bullet proof vests
Both α -helix and β pleats are stabilized by hydrogen bond.
Protein tertiary structure-3D structure.
Proteins made up of single polypeptide such as the oxygen storage protein in muscles called myoglobin folds into a globular structure which is described as its tertiary structure. This protein has 8 helices interconnected with unstructured peptide chain and helix packed against each other leaving a compact globular or spheroidal structure. Most soluble proteins are globular in nature although they may consist of only helix or helix and pleats as a tertiary structure of GFP.
Protein Quaternary structure –
Multimeric protein which have more than one polypeptide chain interact with their sub-units to form compact 3-D structures known as quaternary structure. Such as hemoglobin an oxygen transporter protein found with erythrocytes has 4 sub-units which interact with each other (as α2 β2). The importance of these interactions in hemoglobin is to confers unique oxygen transport function unlike in the single sublimit containing myoglobin which is a structure of normal haemoglobin molecule
Enzymes-the catalysts
A catalyst is a reagent which accelerated a reaction. In an organism many reactions are taking place at any given moment and without enzyme no biological reaction would be possible.
For example -In the blood of animals $CO_2$, generated as a metabolic waste product is mainly carried as bi-carbonate which is formed by the action of the enzyme carbonic anhydrase under normal pressure condition. The dissolution of CO2, in water to form be-carbonate which is negligible is enhanced 10 times in the presence of carbonic anhydrates.
Properties of enzyme
(1)Enzymes are highly specific. For example, an enzyme which catalyzes the hydrolysis of protein cannot catalyzes of hydrolysis of nucleic acid although in both reaction water is added across a covalent bond.
(2) Enzymes are able to enhance reaction rate at ordinary room temperature and normal atmospheric temperature.
(3) Enzymes can be regulated. If excess of a product is made which is against the cell economy, the enzyme is made to slow down by the interaction of the product with the enzyme. A phenomenon called feedback inhibition. Enzymes which are controlled by feedback inhibition are known as regulatory enzyme.
(4) Enzyme is also affected by substrate concentration.
(5) Enzyme activity is also affected by PH.
Catalytic power of enzyme
An enzyme is usually a large molecule which binds to its substrate converting it into product. The region where the substrate binds to the enzyme is known as substrate binding side or active site because it is at this site that activity leading to product formation takes place. The substrate has to diffuse and find the active site. Once it diffuses into the active site in the enzyme conformational changes occur and the substrate molecule are correctly oriented so that groups are easily transferred leading to product formation. Substrate are also distorted by binding to the enzyme active site and this causes certain bonds to break easily and new bonds to form which leads to product formation. An enzyme is made up of variety of amino acid residue some of which contribute to acid base catalysis at the active site.
The activity of enzyme is measured in ICV International unit.
Question
Define 1IU. Answer
An IU is the activity of the enzyme which can catalyze the conversion of 1H mole of substrate to product in one minute at room temperature (usually taken to be 250C).
Question
How PH and temperature affect enzyme activity Answer
heat and extremities of PH disrupt the 3-D structure of an enzyme protein leading to denaturation and loss of catalytic activity.
Uses of enzymes in biotechnology
Enzymes are indispensable to biological system. If important enzyme of a given organism is targeted by substrate like molecules (inhibitors) which do not undergo reaction but binds tightly to the enzyme that its activity is lost organism will perish. This is the basis of action of many antibiotics that target a variety of antibiotics.
Bacterial cell wall is made up of peptidoglycan and its biosynthesis require activity of enzyme transpeptidase. The antibiotic penicillin is a potent inhibitor of the transpeptidase rendering the bacterial cell wall weak and susceptible to host destruction mechanism.
Pharmaceutical companies are constantly on the lookout for natural and designed infiltrator which can specifically target key enzymes of pathogenic bacteria.
Scientist involved in drug discovery research can design antibiotics in silico.
Restriction endonucleases which cut DNA precisely at certain sequences, preparing them for recombinant DNA technology/genetic modification.
Other uses of enzyme include their use in the food industry (use of proteolytic enzyme papain as a meat tenderizer). As Reagent in diagnostic tests (Elisa test) and their role as therapeutic reagents in medicine streptokinase administered after stroke
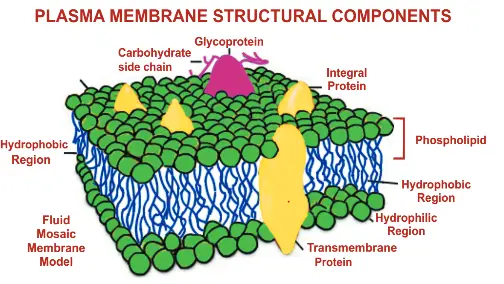
Lipids- the bimolecular (the barriers)
Lipids are special group of bimolecular which have little or no solubility in water but are freely soluble in organic solvent such as chloroform .Several biologically important lipids show amphipathic character that is, they have dual properties of hydrophilicity (water liking) and hydrophilicity (water hating). This make them ideal for formation of bio membranes. All biological structures such as cells bacteria and organelles are covered by membranes which are strong and impermeable that protect cytoplasmic content from osmotic changes. The lipids are phospholipids and proteins are glycoprotein. Function of bio-membrane
(1) Due to their dual character of having an internal hydrophobic region and an external hydrophilic portion, it prevent cellular content from spilling out or extracellular constituent for entering in and also provide semi-permeable nature to plasma membrane.
(2) Water soluble molecules such as sugar, amino acid and salts cannot freely penetrate the lipid membrane they require any carrier protein or channel protein to facilitate transport.
(3) Membranes are the locales where important cellular processes such as cell-cell recognition, cell signaling, and energy generation oxidative phosphorylation take place.)